|
| |
Entity Extraction
|
|
| |
With Text Mine, you can extract
people names, places, organizations, and entities from text.
For example, the following entities will be extracted from
|
|
| |
The growing popularity of Linux in Asia, Europe, and the U.S.
is a major concern for Microsoft. It costs less than 1 USD
a month to maintain a Linux PC in Asia. By 2007, over 500,000
PCs sold in Asia maybe Linux based.
|
|
| |
|
Token |
Type |
|
Linux |
Tech |
|
Asia |
place |
|
Europe |
place |
|
U.S. |
place |
|
Microsoft |
org |
|
1 |
number |
|
USD |
currency |
|
PC |
tech |
|
2007 |
number |
|
500,000 |
number |
|
PCs |
miscellaneous |
|
|
|
| |
The type of the entities extracted depends on the contents of
dictionary tables for people, places, and organizations. The
dictionaries can be customized by adding entities for a
particular technology or include new entities.
|
|
| |
Modules
|
|
| |
Entity
- The text is passed to the entity_ex
function from which entities are extracted. Each entity is assigned
a type. This function also returns the sentences where entities
occur (which is useful to identity key sentences for questions).
See tx_entities.pl in the cgi-bin
directory.
|
|
| |
Function Calls for Entity_ex
|
|
| |
The entity_ex
function uses text_split to generate
sentences from the passed
text. If the text is not well formatted (text from a web page),
then the text_split function will attempt to split the text
into chunks using vectors. Adjacent chunks of text will be
compared to check for a break. A well formatted article like
a news articles will be split into sentences.
For each sentence, tokens will be extracted using
assemble_tokens . In the first pass, the tokens will first
be classified into potential entities with associated entity types.
In subsequent passes, the types of each entity will be evaluated
using context as well as rules for entities in a table. Finally,
the most likely entity type will be set for every potential entity.
|
 |
|
| |
POS Tagger
|
|
| |
The parts of speech tagger classifies the words in text into one
of 8 parts of speech. For example, the sentence -
Albert Einstein was one of the greatest scientists of all time.
would be classified as follows -
|
|
| |
|
Token |
POS Type |
|
Albert Einstein |
noun |
|
was |
verb |
|
one |
adjective |
|
of |
preposition |
|
the |
determiner |
|
greatest |
adjective |
|
scientists |
noun |
|
of all time |
adverb |
|
. |
punctuation |
|
|
|
| |
Modules
|
|
| |
Pos
- The text is passed to the pos_tagger
function from which parts of speech are extracted. Each token is
assigned a type that is chosen from the list of possible types
for the token. The most likely POS for the token is selected
using context and frequency of occurrence.
See tx_pos.pl in the cgi-bin
directory.
|
|
| |
Function Calls for Pos_tagger
|
|
| |
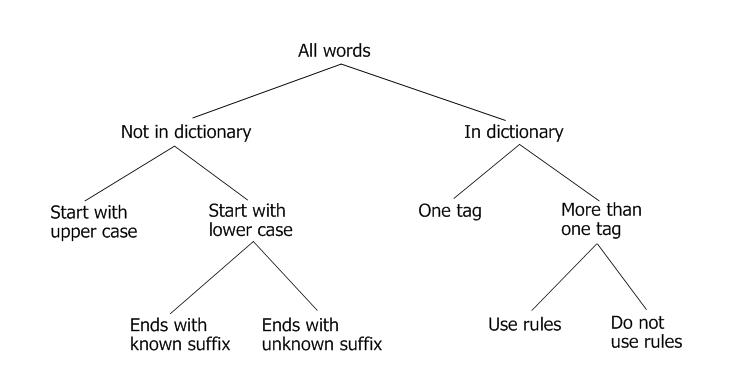
The pos_tagger
function calls lex_tagger
which uses the dictionary to find the list of potential
tags for any word. The tagger then scans the list of
tokens and associated tags returned by the
lex_tagger and uses rules and frequency of tag
usage to set a single tag for every token.
|
 |
|
A Decision Tree for a Part of Speech Tagger |
|
| |
Projects
|
|
| |
1. Generate more training data to build an improved set of rules
for extracting entities.
2. Adding and correcting entries in the entity dictionaries
3. Improve the Parts of Speech Tagger with more training data
and verify rules.
|
|