|
|
| Home | About | Install | FAQ | Screens | Tools | ||||||
| Search | Extract | Q & A | Cluster | Dictionary | |||||||
| Clustering | |||||||
| The cluster module accepts a list of documents and returns a collection of clusters. Each cluster consists of a variable number of documents. A cluster is created by locating all similar documents within the list of documents. The title of the cluster is a set of the 3 most frequent 2 or more word phrases found in the documents that make up the cluster. | |||||||
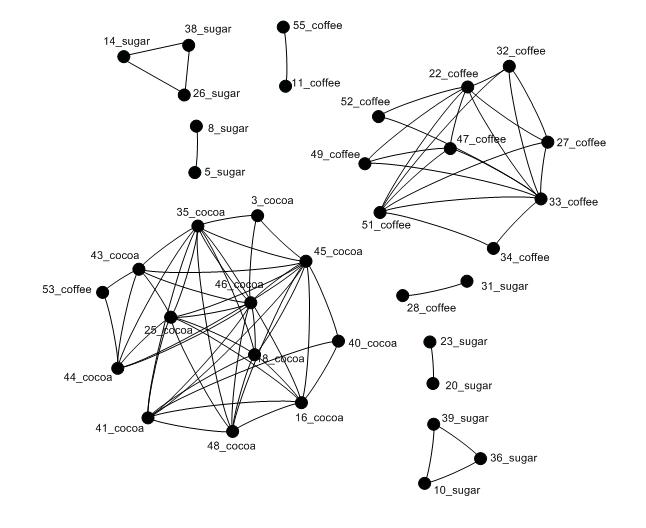
| A similarity matrix of the document collection is generated. A genetic algorithm is used to arrange the documents such that 'close' documents are near each other. Clusters are built around 'key documents' (those documents that have a high degree of similarity with multiple documents). Finally, any documents that cannot be placed in a cluster are saved in the miscellaneous cluster. | |||||||
| News Monitor | |||||||
| The News Monitor periodically collects news articles from the web. The text of the news articles are clustered and saved. Instead of scanning a stream of articles one at a time, the list of clusters describes the range of articles at a glance. You can quickly focus on a cluster of articles of interest. | |||||||
| Modules | |||||||
| Cluster - This module contains the functions to generate clusters using a genetic algorithm. The set of documents passed are converted to vectors and the similarity matrix for the documents is built. The GA is used to arrange documents such that close documents are near each other. Clusters are built using 'key documents' are centers. | |||||||
| Function Calls for cluster | |||||||
|
The cluster function
accepts a list of documents and returns a list of clusters.
The sim_matrix function
is first called to generate a similarity matrix. The similarity
matrix uses the cosine measure to compare pairs of document
vectors. Next, the genetic algorithm is run to order the
list of documents by similarity. The functions to select parents,
implement crossover and mutation, and to dump results are called
as necessary.
| |||||||
| |||||||
| Similarities between documents in a collection | |||||||
| Summarization | |||||||
| Text Mine can summarize news articles in brief or full. The brief summary is a few key phrases strung together. The full summary identifies the key sentences in articles. A key sentence is a sentence that appears to be a leading or important sentence compared to all other sentences in the articles. Other key sentences are selected based on their relationship with the existing key sentences and the remaining sentences in the article. For example, the brief and full summary for the following articles is | |||||||
Eastman Kodak Co said it is introducing four information technology
systems that will be led by today's highest-capacity system for data
storage and retrieval. The company said information management products
will be the focus of a multi-mln dlr business-to-business communications
campaign under the threme "The New Vision of Kodak."
Noting that it is well-known as a photographic company,
Kodak said its information technology sales exceeded four
billion dlrs in 1986. "If the Kodak divisions generating those
sales were independent, that company would rank among the top
100 of the Fortune 500," it pointed out.
The objective of Kodak's "new vision" communications
campaign, it added, is to inform others of the company's
commitment to the business and industrial sector.
Kodak said the campaign will focus in part on the
information management systems unveiled today --
-- The Kodak optical disk system 6800 which can store more
than a terabyte of information (a trillion bytes).
- The Kodak KIMS system 5000, a networked information
management system using optical disks or microfilm or both.
-- The Kodak KIMS system 3000, an optical-disk-based system
that allows users to integrate optical disks into their current
information management systems.
-- The Kodak KIMS system 4500, a microfilm-based,
computer-assisted system which can be a starter system.
Kodak said the optical disy system 6800 is a
write-once/ready-many-times type its Mass Memory Division will
market on a limited basis later this year and in quantity in
1988.
Each system 6800 automated disk library can accommodate up
to 150, 14-inch optical disks. Each disk provides 6.8 gigabytes
of randomly accessible on-line storage. Thus, Kodak pointed
out, 150 disks render the more-than-a-terabyte capacity.
Kodak said it will begin deliveries of the KIMS system 5000
in mid-1987. The open-ended and media-independent system
allows users to incorporate existing and emerging technologies,
including erasable optical disks, high-density magnetic media,
fiber optics and even artificial intelligence, is expected to
sell in the 700,000 dlr range.
Initially this system will come in a 12-inch optical disk
version which provides data storage and retrieval through a
disk library with a capacity of up to 121 disks, each storing
2.6 gigabytes.
Kodak said the KIMS system 3000 is the baseline member of
the family of KIMS systems. Using one or two 12-inch manually
loaded optical disk drives, it will sell for about 150,000 dlrs
with deliveries beginning in mid-year.
The company said the system 3000 is fulling compatibal with
the more powerful KIMS system 5000.
It said the KIMS system 4500 uses the same hardware and
software as the system 5000. It will be available in mid-1987
and sell in the 150,000 dlr range.
| |||||||
Brief summary (4 chunks):
... four information technology systems that will be led by today's ...
...highest-capacity system for data storage and ...
...Eastman Kodak Co said it is introducing ...
... for about 150,000 dlrs with deliveries beginning in mid-year...
| |||||||
Full Summary (2 sentences):
Eastman Kodak Co said it is introducing four information technology
systems that will be led by today's highest-capacity system for
data storage and retrieval.
The open-ended and media-independent system allows users to
incorporate existing and emerging technologies, including erasable
optical disks, high-density magnetic media, fiber optics and even
artificial intelligence, is expected to sell in the 700,000 dlr range.
| |||||||
| Modules | |||||||
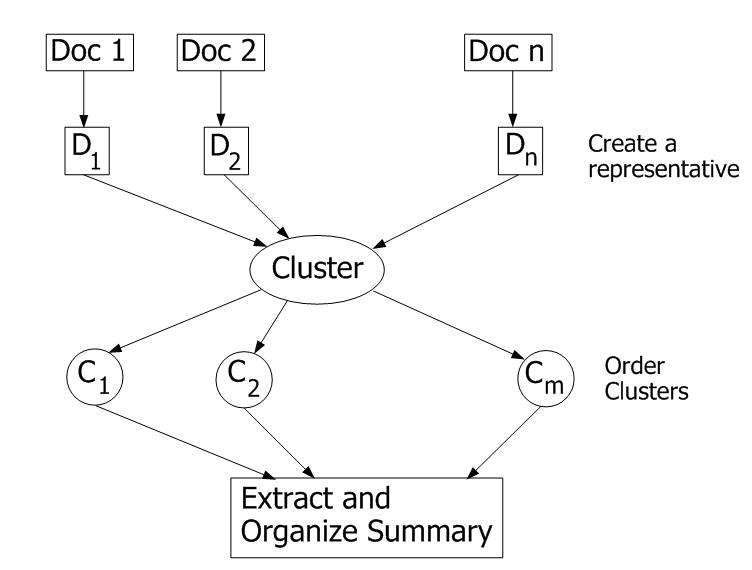
| Summary - This module receives a text document and splits it into text chunks (sentences). Each text chunk is expanded using a thesaurus. The collection of text chunks are clustered. From the top 3 clusters, the text chunk with the highest similarity with all other text chunks in the cluster, is extracted and presented as the summary. In the brief version of summary, only a snippet of text and not the whole sentence is presented. | |||||||
| Function Calls for summary | |||||||
|
The summary function
accepts a documents and returns a brief or long summary.
The text_split function
splits the text into sentences. The
content_words function extracts the content words
in each sentence. These words are expanded using the
similar_words function.
Next, the clustering function is called to build clusters around the expanded sentences. A centroid vector is created for each cluster except the miscellaneous cluster. The member document vectors are compared with the centroid vector and the member with the highest similarity to the centroid is selected as a key sentence for the summary. The key sentences are extracted from clusters in ascending order of the size of clusters. | |||||||
| |||||||
| Cluster-based summarization of multiple documents | |||||||
| Projects | |||||||
|
1. Verify clustering algorithm - test with different collections
of documents. 2. Improve scalability of algorithm - optimize the computations 3. Verify summarization code. | |||||||