|
| |
Dictionary
|
|
| |
The Text Mine dictionary is based on
WordNet
developed by the Cognitive Science Laboratory at Princeton
University. The dictionary file data is converted to tables
and stored in a MySql database. The tables include synonym
sets for words, relationships between words, relationships
between synonym sets, and examples of usage.
|
|
| |
For each word, the different parts of speech categories
to which it may belong as well as the different senses
are shown. Each entry has an example of usage. A number
is associated with each sense. This is a 'tag sense' that
roughly indicates the frequency with which the sense
occurs compared to other senses. A tag count is not always available
for every word sense.
|
|
| |
If a word is mispelled, Text Mine will find the 12 nearest
words. The nearest words are located by stripping the last
character of the search word and finding all close words.
This process ends when 12 or more words have been found.
|
|
| |
Modules
|
|
| |
WordNet -
This module contains functions to manipulate the WordNet
database tables in Text Mine. The functions include checking
if a word exists in the dictionary, all words that are related
(synonyms, antonyms, hypernyms) to this word, and other functions.
An example of usage can be found in the
wn_dict.pl CGI script.
|
|
| |
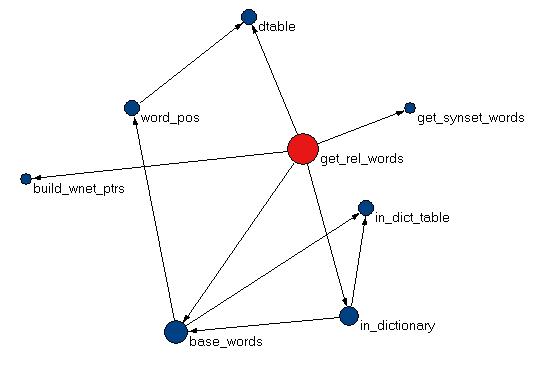
Function Calls for get_rel_words
|
|
| |
The get_rel_words function
accepts a word and a list of the relationships. For each
relationship, the words associated with the word are collected
in a hash. The in_dictionary
function is used to check if the word exists in the dictionary
or not. The get_synset function
is called to get all the synset words for the synsets in which
the word participates.
|
|
| |
|
|
| |
Projects
|
|
| |
1. The list of function words is not complete. The Text Mine dictionary
a combination of the WordNet words and a much smaller list of
function words (conjunctions, prepositions, etc.)
2. Add functions to compute the anagrams of a word that exist in
the dictionary. Compute anagrams of various word lengths.
|